Python コード集
講義で使用するpythonのコードを以下に載せています.必要に応じてコピーして使用してください.プログラムの詳細は授業内で配布している資料を参照してください.
目次
クリックすることで該当のコードにジャンプします.戻る時はブラウザーの「戻る」を使用してください.
使い方
データの取得
app_idには各自が取得したapp idを入れてください.以下のコードで国内総生産のデータ系列が取得できます.
stats_data_id = '0004028585'
cat01_code = '17'
df = get_estat_data_by_cat01(app_id, stats_data_id, cat01_code)
print(df.head())
データのプロット
データ系列のグラフを描くことができます.
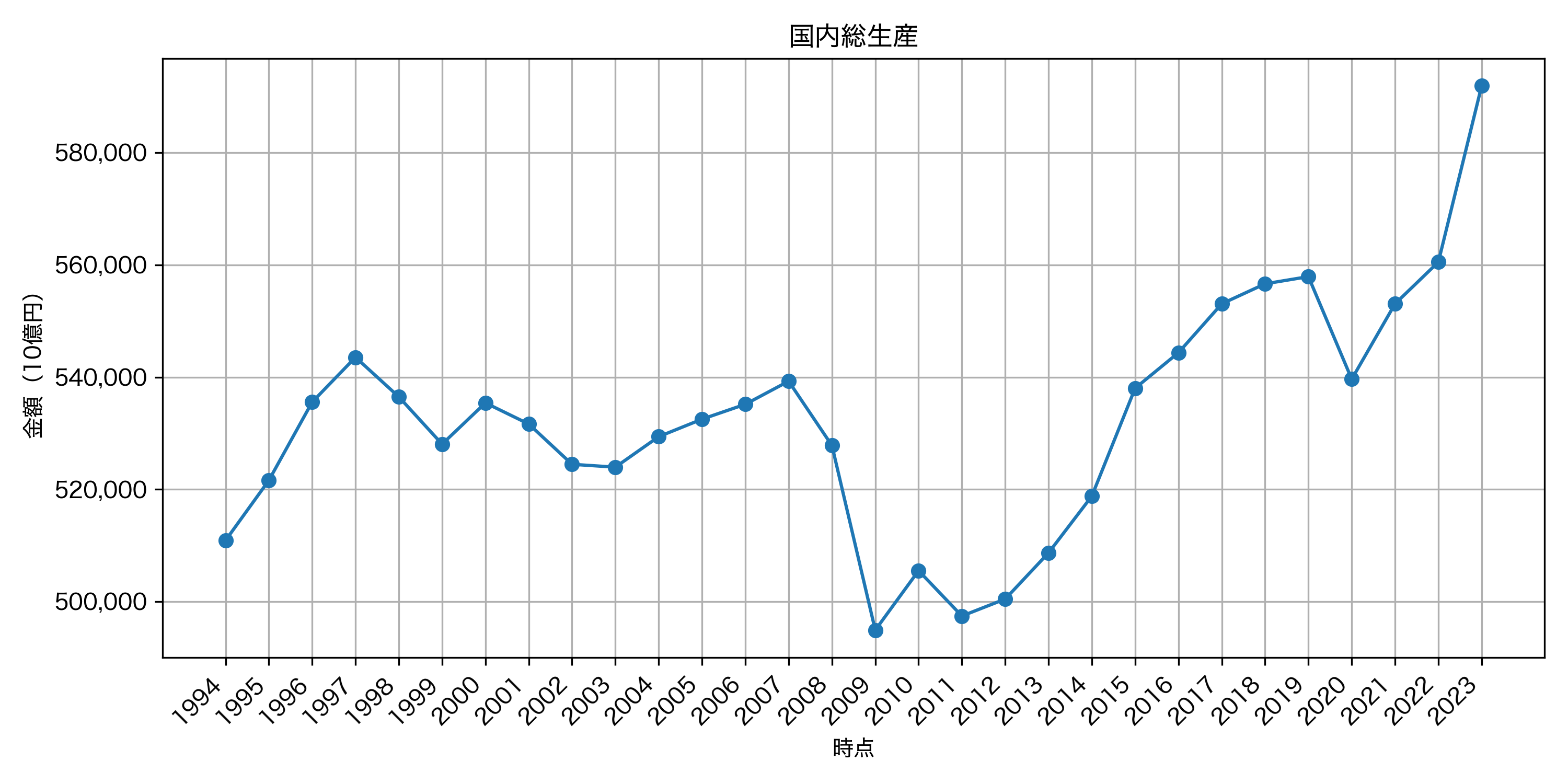
plot_estat_series_autotime(df, title='国内総生産', ylabel='金額(10億円)')
以下のようなグラフが作成できます.
Python コード
ライブラリのインポート
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.ticker import StrMethodFormatter
plt.rcParams['font.family'] = 'Hiragino Sans'
import requests
import subprocess
import re
統計表IDの検索
e-Stat APIのgetStatsListを使って,指定したキーワードに一致する統計表IDとタイトルを取得する関数
def get_estat_stats_list(app_id, search_word, lang="J", limit=100):
"""
e-Stat APIのgetStatsListを使って、指定したキーワードに一致する統計表IDと
タイトルを取得する。
Parameters:
app_id (str): e-StatのアプリケーションID
search_word (str): 検索キーワード(例:"国民経済計算")
lang (str): 言語コード("J"=日本語、"E"=英語)。デフォルトは"J"
limit (int): 最大取得件数(デフォルト100件)
Returns:
list of dict: 統計表のIDとタイトルのリスト(例:[{id: ..., title: ...}, ...])
"""
url = "https://api.e-stat.go.jp/rest/3.0/app/json/getStatsList"
params = {
"appId": app_id,
"searchWord": search_word,
"lang": lang,
"limit": limit
}
response = requests.get(url, params=params)
response.encoding = 'utf-8'
if response.status_code != 200:
raise Exception(f"API呼び出し失敗(HTTP {response.status_code})")
try:
tables = response.json()["GET_STATS_LIST"]["DATALIST_INF"]["TABLE_INF"]
results = [{"id": entry["@id"],
"title": entry["TITLE"]["$"]} for entry in tables]
return results
except KeyError:
print("レスポンスの構造が想定外です。内容を確認してください:")
print(response.json())
return []
TABLE_INF のネスト構造の平坦化
e-Stat の TABLE_INF のネスト構造を平坦化して,1行のDataFrameに変換する関数
def flatten_table_info(table_info_dict):
"""
e-Stat の TABLE_INF のネスト構造を平坦化して、1行のDataFrameに変換する。
Parameters:
table_info_dict (dict): TABLE_INF の辞書データ
Returns:
pd.DataFrame: 1行のDataFrame(各要素が列)
"""
flat_data = {}
for key, value in table_info_dict.items():
if isinstance(value, dict):
# ネストされた辞書
#(例:'STAT_NAME': {'@code': '001', '$': '統計名'})
for sub_key, sub_val in value.items():
flat_key = f"{key}.{sub_key}"
flat_data[flat_key] = sub_val
else:
# 単一の値
flat_data[key] = value
return pd.DataFrame([flat_data])
統計表の基本情報(TABLE_INF)とデータ系列(cat01分類)の一覧を取得
e-Stat APIから統計表の基本情報(TABLE_INF)とデータ系列(cat01分類)の一覧を取得する関数
def get_estat_metadata(app_id, stats_data_id):
"""
e-Stat APIから統計表の基本情報(TABLE_INF)と
データ系列(cat01分類)の一覧を取得する(データ本体は含まない)
Parameters:
app_id (str): e-StatのアプリケーションID
stats_data_id (str): 統計表ID
Returns:
tuple:
- dict: 統計表の基本情報(TABLE_INF)
- pd.DataFrame: データ系列(cat01)の一覧(code, name)
"""
url = 'https://api.e-stat.go.jp/rest/3.0/app/json/getStatsData'
# e-Stat API パラメータ設定
params = {
'appId': app_id,
# e-Stat アプリケーションID(APIキーをここに指定)
'lang': 'J', # 言語設定: 'J' = 日本語, 'E' = 英語
'statsDataId': stats_data_id,
# 統計表ID(e-Stat の個別統計に対応するID)
'metaGetFlg': 'Y',
# 分類メタ情報(cat01, area など)を取得するか
# ('Y' = 取得, 'N' = 省略)
'cntGetFlg': 'N',
# データ件数のみ取得するか ('Y' = 件数だけ, 'N' = データ本体を取得)
'explanationGetFlg': 'Y',
# 統計表の説明文を取得するか ('Y' = 取得, 'N' = 省略)
'annotationGetFlg': 'Y',
# 注記・脚注の情報を取得するか ('Y' = 取得, 'N' = 省略)
'sectionHeaderFlg': '1',
# 表章項目(ヘッダー情報)を取得するか ('1' = 含める, '0' = 含めない)
'replaceSpChars': '0'
# 特殊文字をHTMLエンティティなどに置換するか
# ('0' = そのまま, '1' = エスケープ)
}
response = requests.get(url, params=params)
data = response.json()
if data['GET_STATS_DATA']['RESULT']['STATUS'] != 0:
raise Exception(f"e-Stat APIエラー: {data['GET_STATS_DATA']
['RESULT']['ERROR_MSG']}")
stat_data = data['GET_STATS_DATA']['STATISTICAL_DATA']
table_info_raw = stat_data['TABLE_INF']
df_table_info = flatten_table_info(table_info_raw)
# 統計表の基本情報
table_info = stat_data['TABLE_INF']
# データ系列(cat01)一覧の抽出
class_objs = stat_data['CLASS_INF']['CLASS_OBJ']
cat01_list = []
for obj in class_objs:
if obj['@id'] == 'cat01':
for item in obj['CLASS']:
cat01_list.append({
'cat01': item['@code'],
'name': item['@name']
})
df_cat01 = pd.DataFrame(cat01_list)
return df_table_info, df_cat01
統計表IDとcat01コードに対応するデータを取得
指定した統計表IDとcat01コードに対応するデータをe-Stat APIから取得する関数
def get_estat_data_by_cat01(app_id, stats_data_id, cat01_code):
"""
指定した統計表IDとcat01コードに対応するデータをe-Stat APIから取得。
Parameters:
app_id (str): e-StatのアプリケーションID
stats_data_id (str): 統計表ID(statsDataId)
cat01_code (str): 取得対象のデータ系列コード(例:'0001')
Returns:
pd.DataFrame: 該当cat01のデータ(time, area, cat01, value)
"""
url = 'https://api.e-stat.go.jp/rest/3.0/app/json/getStatsData'
params = {
'appId': app_id,
'lang': 'J',
'statsDataId': stats_data_id,
'cdCat01': cat01_code, # ← ここでcat01をフィルタ
'metaGetFlg': 'N',
'cntGetFlg': 'N',
'explanationGetFlg': 'N',
'annotationGetFlg': 'N',
'sectionHeaderFlg': '1',
'replaceSpChars': '0'
}
response = requests.get(url, params=params)
data = response.json()
if data['GET_STATS_DATA']['RESULT']['STATUS'] != 0:
raise Exception(f"e-Stat APIエラー: {data['GET_STATS_DATA']['RESULT']
['ERROR_MSG']}")
records = data['GET_STATS_DATA']['STATISTICAL_DATA']['DATA_INF']['VALUE']
df = pd.DataFrame([{
'time': rec.get('@time'),
'area': rec.get('@area'),
'cat01': rec.get('@cat01'),
'value': rec.get('$')
} for rec in records])
return df
e-Stat の time コードから表示用ラベル(年・月・四半期)を生成
e-Stat の time コードから表示用ラベル(年・月・四半期)を生成する関数
def parse_time_label(time_code):
"""
e-Stat の time コードから表示用ラベル(年・月・四半期)を生成
例:
2020010000 → 2020-01
2020040101 → 2020Q1
1980000000 → 1980
"""
time_code = str(time_code)
if re.match(r'^¥d{4}000000$', time_code):
# 年次
return time_code[:4]
elif re.match(r'^¥d{6}0000$', time_code):
# 月次(例:2023010000)
year = time_code[:4]
month = time_code[4:6]
return f"{year}-{month}"
elif re.match(r'^¥d{6}010[1-4]$', time_code):
# 四半期(例:2020010101 → Q1)
year = time_code[:4]
q_map = {'01': 'Q1', '02': 'Q2', '03': 'Q3', '04': 'Q4'}
q = q_map.get(time_code[-2:], '')
return f"{year}{q}"
else:
return time_code # 変換できない場合はそのまま返す
e-Stat の time コードを自動整形し、折れ線グラフとしてプロット
e-Stat の time コードを自動整形し、折れ線グラフとしてプロットする関数
def plot_estat_series_autotime(df, title='e-Stat 時系列グラフ',
ylabel='値', xlabel='時点',
figsize=(10, 5), savefile=None, dpi=300):
"""
e-Stat の time コードを自動整形し、折れ線グラフとしてプロット。
Y軸は3桁ごとにカンマ区切り。
Parameters:
df (pd.DataFrame): 'time' と 'value' を含む DataFrame
"""
df = df.copy()
df['label'] = df['time'].apply(parse_time_label)
df['value'] = pd.to_numeric(df['value'], errors='coerce')
df_sorted = df.sort_values('label')
plt.figure(figsize=figsize)
plt.plot(df_sorted['label'], df_sorted['value'], marker='o', linestyle='-')
plt.title(title)
plt.xlabel(xlabel)
plt.ylabel(ylabel)
plt.xticks(rotation=45, ha='right')
# ✅ 3桁ごとにカンマを追加
ax = plt.gca()
ax.yaxis.set_major_formatter(StrMethodFormatter('{x:,.0f}')) # 小数なし
plt.grid(True)
plt.tight_layout()
# ✅ 保存処理(指定された場合)
if savefile:
plt.savefig(folder_path+savefile, dpi=dpi)
print(f'グラフを保存しました: {savefile}')
plt.show()
コードのタイトル
コードの説明e-Stat
ここにコードを書く
コードのタイトル
コードの説明e-Stat
ここにコードを書く
コードのタイトル
コードの説明e-Stat
ここにコードを書く
コードのタイトル
コードの説明e-Stat
ここにコードを書く